Компания IBM представила демо-версию своего нового инструмента: Tone Analyzer, призванного распознавать и корректировать «эмоциональные тона, социальные наклонности и индивидуальные стили в письменной речи». Другими словами, IBM хочет сделать нас лучшими авторами.
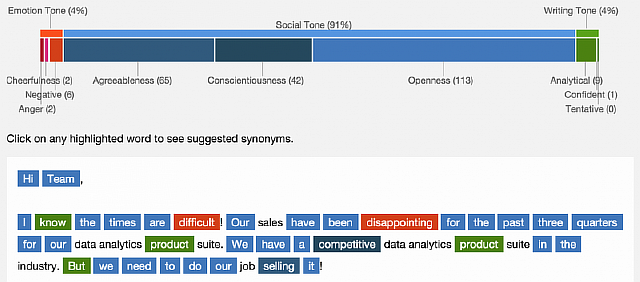
Журналист известного издания «Popular Science» Дэйв Гершгорн решил проверить, как работает новая система компании. Для этого он загрузил в анализатор случайное письмо Марка Твена, написанное в 1876 году, и свой собственный емейл одному из редакторов журнала.
Результаты анализа оказались на удивление схожими. Tone Analyzer исследовал текст по трём категориям: эмоциональный тон, социальный тон, и писательский тон. Внутри этих категорий Твен набрал 4% в эмоциональной, 88% в социальной и 7% в писательской. Гершгорн получил 2, 90, и 6 процентов соответственно. (При этом неучтенные проценты, по всей видимости, приходятся на имена собственные и другие слова, которые компьютер не понимает). Также система сделала в текстах дополнительные отметки – например, выделила слова, которые она посчитала воодушевляющими и вдохновляющими. Твен использовал 4 таких слова, Дэйв – всего одно.
Что демонстрируют эти результаты? В основном, ключевую проблему этой программы: она не анализирует контекст написанного слово за словом. Фраза «Я рассержен» даёт в данном случае такой же «рассерженный» результат, как и фраза «Я не рассержен», поскольку компьютер читает лишь по одному слову за раз. Это позволяет системе эффективно находить отдельные слова, которые могут вызвать нежелательную реакцию, но не даёт ей видеть большую картину, стоящую за этими словами.
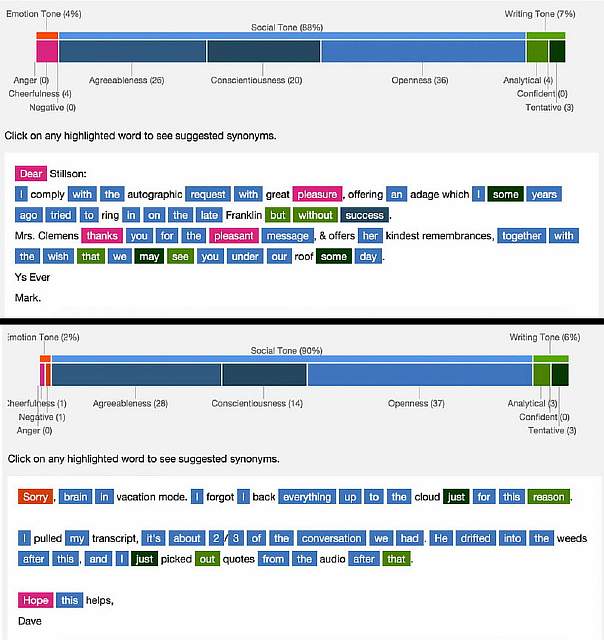
Анализ письма Марка Твена 1876 года и современного емейла
Tone Analyzer не единственный, и совершенно точно не первый писательский инструмент, который не оправдывает надежд – но важно отметить, что он пока ещё только находится в разработке. Разумеется, если программа действительно хочет извлекать из текста социальные подсказки и работать с литературными стилями, ей необходимо анализировать больше, чем одно слово за раз.
Эта особенность свойственна большинству программ совершенствования писательского мастерства: они просто не способны понимать письменный текст, который генерирует человек, 100 процентов времени – хотя некоторые подбираются невероятно близко.
Компания Automated Insights, которая объединилась с агентством Associated Press для генерации спортивных новостей, решила использовать программы распознавания языка в обратную сторону. Достаточно ввести в систему некоторые чёткие данные, вроде счёта матча, и компьютер подберёт из своего банка необходимые глаголы и прилагательные для описания этих данных. Этот процесс обратен анализу написанного материала, но использует ту же идею: программа помогает создать читаемый и стилистически правильный текст.
Однако инструмент IBM вовсе не ужасен – он читает текст слово за слово и идентифицирует распространённые коннотации, связанные с этими словами. Такая система может быть без сомнения полезной, если её интегрировать, к примеру, в емейл-клиент или профессиональный мессенджер-сервис.
Свежие комментарии